-
 Sunset_Yuhi
Sunset_Yuhi
- 5789
- 9
- 2
- 0
-

- いいね!0
kampfer
@kampfer2009
「togetterユーザ動向をちょっと調べてみた」をトゥギャりました。 togetter.com/li/1207544
2018-03-11 20:15:33
Togetter(トゥギャッター)
@togetter_jp
「「テキストマイニングによるTwitter個人アカウントの性格推定」反応まとめ in PyConJP2018」togetter.com/li/1281224 が伸びてるみたい。いま話題みたいですよ? 作成者:@jumpyoshim
2018-10-27 09:45:07
Togetter(トゥギャッター)
@togetter_jp
「自分のツイートをテキストマイニングして一人反省会をする」togetter.com/li/1282024 が伸びてるみたい。みんなに届けぇ〜 作成者:@Sunset_Yuhi
2018-10-29 08:14:04
サンセット
@Sunset_Yuhi
Twitterのツイート分析は少し面倒そうと思ってたけど、Togetterだとサイトの構造が分かりやすいな。 togetter.com/li/ の後に7桁の数字を付ければ各まとめにアクセスできて、ソースを見ればユーザー名もいいね数も分かる。記事数は多いけど、適度にサンプル取れば有意な結果にはなるだろう。
2018-12-29 17:40:33
サンセット
@Sunset_Yuhi
Togetterのrobots.txtを読むと、個人のスクレイピングにあまり制約はないっぽい。 togetter.com/robots.txt Python側で使えそうなのは、web取得用でurllibやRequests。スクレイピング用でBeautiful SoupやSelenium、Pandasも使える。 【Python入門】Webスクレイピングとは? blog.codecamp.jp/python-scraping
2018-12-30 02:40:12
サンセット
@Sunset_Yuhi
Togetterのスクレイピング、実質的に10行くらいでできてしまった。ファイル名は思いつきで「Togetter Getter」にした。 このまま2018年に作られた記事を調べようかと思ったけど、10万記事以上あるようなので大変。あと申し訳程度でも、多少はプライバシーも考えるべきか。 pic.twitter.com/7XpqTuyc4B
2018-12-30 09:59:24 拡大
サンセット
@Sunset_Yuhi
拡大
サンセット
@Sunset_Yuhi
Togetterのデータ分析を企むにあたり、問題設定やサンプル数や許容誤差について考えてたのだが、n個の記事をサンプリングして、特定ユーザーのコメント数Xnを数えて標本平均を取れば、平均μで分散σ^2/nの正規分布になるのかな。中心極限定理で。 サンプル数の理論的決め方 naro.affrc.go.jp/org/nfri/yakud…
2018-12-31 14:31:43
サンセット
@Sunset_Yuhi
スクレイピングの練習と思って始めたTogetterのデータ収集、重複なしの乱数を使ってURLにアクセスし、記事名・作成者・閲覧数・コメント数の他、コメント欄の情報も大体取得できた。 あと2018年の記事は、No.1185492~1303972の118481記事(欠番あり)と分かった。もう何でもできてしまう気がするぞ。 pic.twitter.com/UP54Ro39IM
2019-01-01 21:21:07 拡大
サンセット
@Sunset_Yuhi
拡大
サンセット
@Sunset_Yuhi
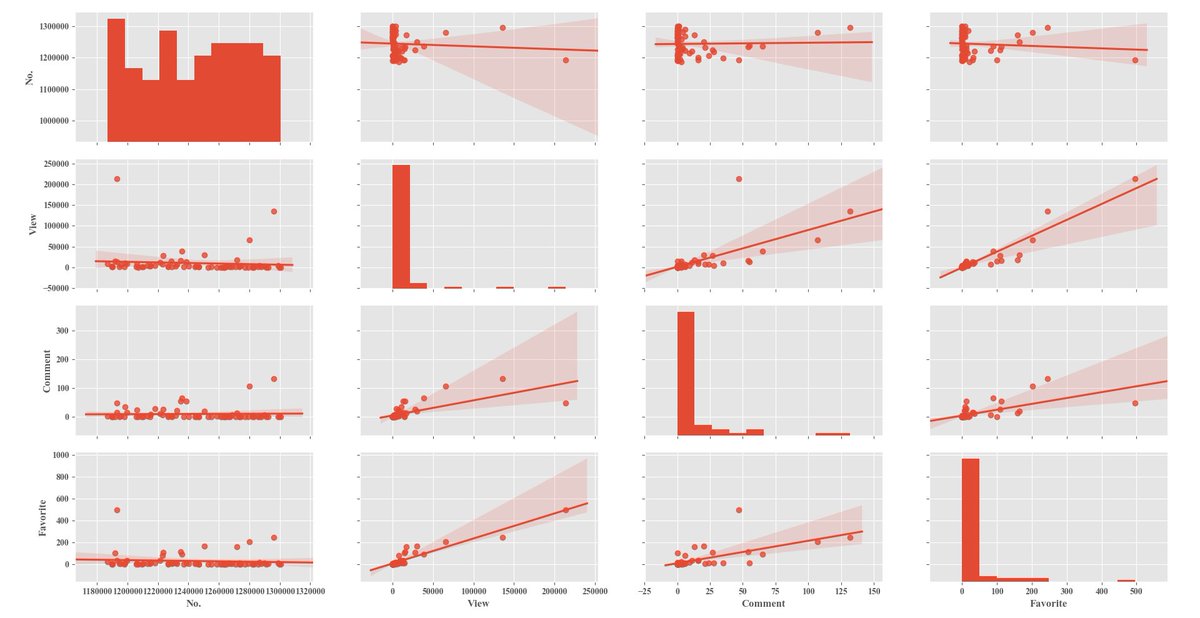
試しにサンプル数100で、2018年の記事をスクレイピング。データを取れた記事は約70、tag数は300弱、comment数は700強。 view、comment、favoriteは対数分布していて、互いに相関がありそう。 tagの種類では、アニメ、ゲーム、マンガあたりが多そうだったけど、view数とかとの関係がよく分からん。 pic.twitter.com/jxdlgBKoVP
2019-01-02 03:56:46 拡大
拡大
 拡大
サンセット
@Sunset_Yuhi
拡大
サンセット
@Sunset_Yuhi
サンプル数200で取った基本統計量と、コメント欄の散布図行列。 1記事あたり、viewは平均7637、中央値1550。コメ数は平均11、中央値1。fav数は平均16、中央値3。カテゴリー別ではサブカルチャーの記事数が一番多かった。 コメントへのfav数は平均9、中央値2。バズった記事のデータはまだ足りないかも。 pic.twitter.com/GCTjonWtA7
2019-01-04 04:30:24 拡大
拡大
 拡大
サンセット
@Sunset_Yuhi
拡大
サンセット
@Sunset_Yuhi
Togetterをスクレイピングして見つけた2018年のすごい記事。記事へのコメント数が1375もある。たまたま見つけたので、2018年で一番多い記事かは不明。 「一番の原因はなんだと思いますか?」自転車と右折車の交通事故のドライブレコーダーを巡り大議論が勃発 - Togetter togetter.com/li/1211850
2019-01-05 13:31:20
サンセット
@Sunset_Yuhi
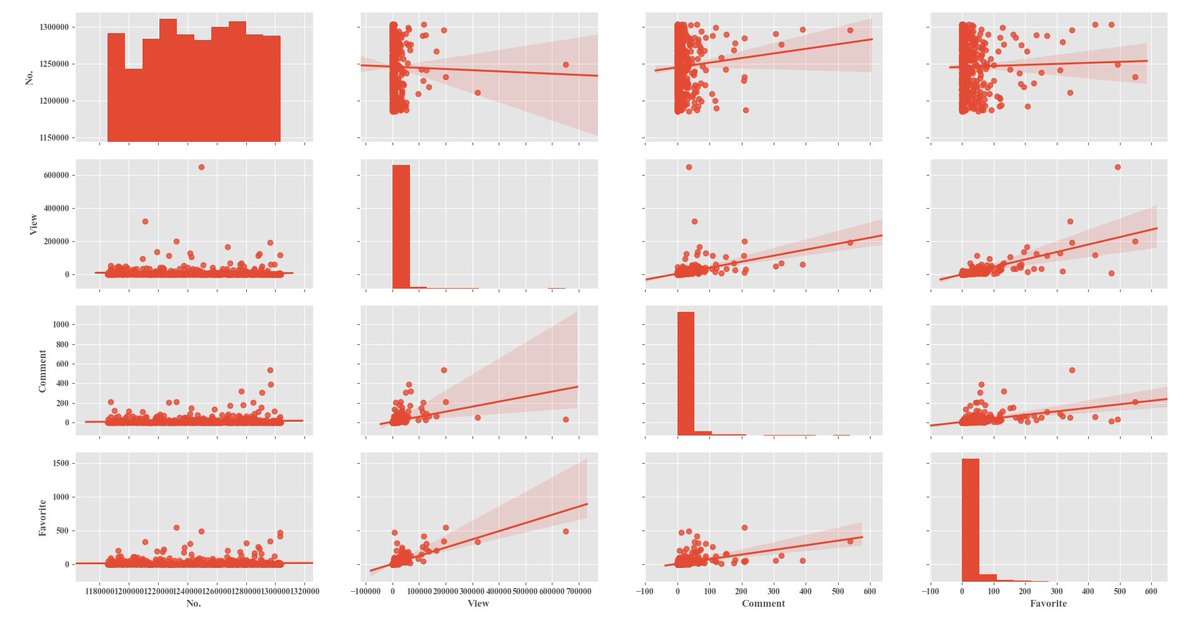
標本数1000(有効な記事数N=743)の結果。散布図で特徴ある記事がいくつか見える。カテゴリー別で見た統計量もかなり興味深い。 そろそろマーケティングっぽいことできそうだけど、記事タイトルやコメントの頻出語とかも見たいかなあ。Janomeで形態素解析からやるか、KH Coderを使ってしまうか。 pic.twitter.com/S6eNHsXlqx
2019-01-05 21:36:23 拡大
拡大
 拡大
サンセット
@Sunset_Yuhi
拡大
サンセット
@Sunset_Yuhi
記事のview数とfav数は割と比例するけど、コメ数は異常に多い記事と少ない記事で二極化しそう。これはview数が65万に対して、コメ数が36と少ない。 【夏休み子ども科学電話相談 180723】カブトムシを洗濯機で洗ったけど大丈夫だった!? 窒息しないカブトムシの秘密 - Togetter togetter.com/li/1249586
2019-01-05 23:50:16
サンセット
@Sunset_Yuhi
743記事からコメントのデータが9000以上取れてたので、試しに共起ネットワークを作ってみた。だけどコメ数が538もある記事があって、結果を引っ張られてしまった。 togetter.com/li/1296287 他は「日本」「被害」の出現回数が多くて、批判的文脈で使われることが多そうだった。要検討。 pic.twitter.com/r0aB5lu4I1
2019-01-06 02:47:06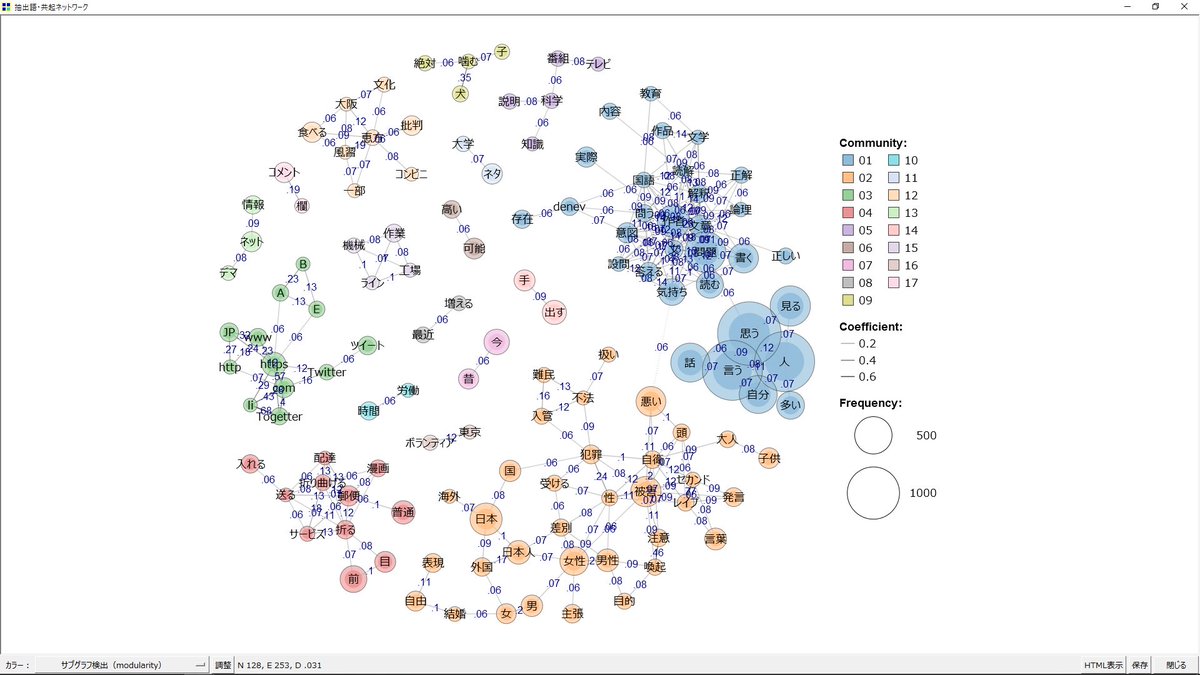 拡大
拡大
 拡大
サンセット
@Sunset_Yuhi
拡大
サンセット
@Sunset_Yuhi
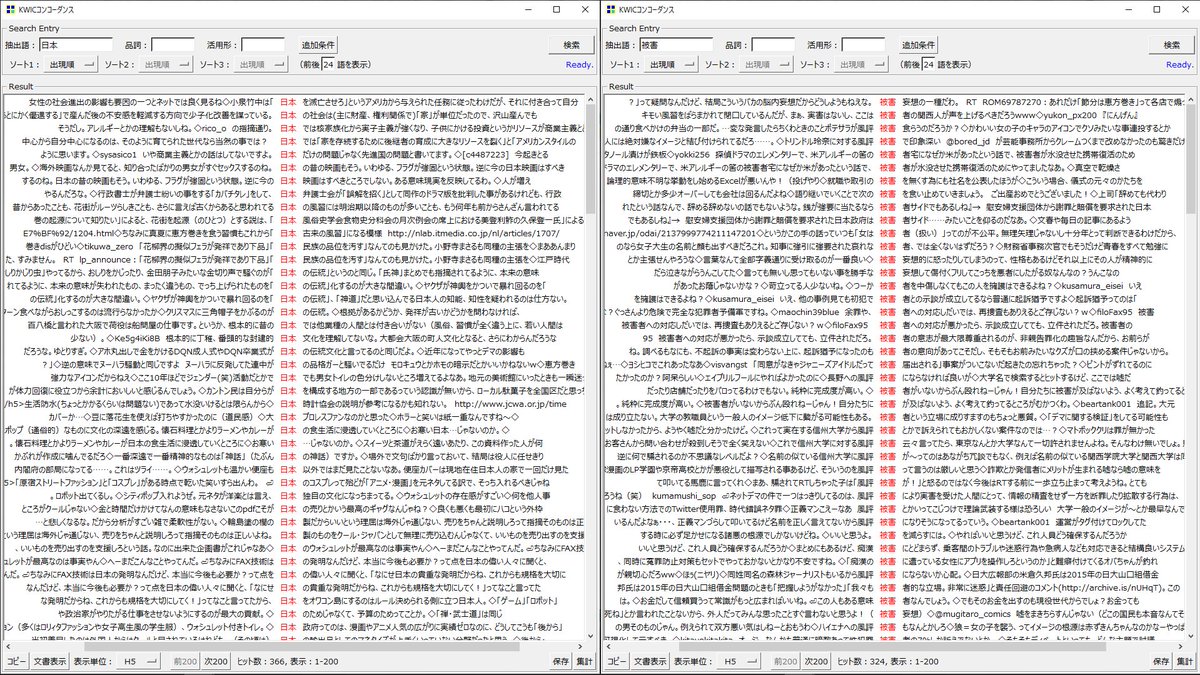
げ、自分も似たことしてたのに先越された! togetter.com/li/1305777#c58… 「2018年 togetter まとめランキング!」togetter.com/li/1305777 にコメントしました。
2019-01-06 11:44:35
サンセット
@Sunset_Yuhi
データが取れた記事は86107/118481=72.7[%]か。3/4くらいしか取れないのは、サンプル数少ない時も同じだったなあ。 あと、ViewとCommentとfavoriteの数も、バズった記事ほどバラつきが大きいのは予想していた。けれどだんだん、「バズる」の基準もどうすべきか問題になりそう。四分位数で判断するか。
2019-01-07 00:47:45
サンセット
@Sunset_Yuhi
30位までの2018年ランキング面白いな。View数順ではエンタメカテゴリだけで10記事ある。Comment数順では社会とサブカルチャーのカテゴリで、それぞれ10記事ある。Favorite数順では生活カテゴリだけで13記事ある。かなり傾向が分かれている。
2019-01-07 19:14:21
サンセット
@Sunset_Yuhi
ネガポジ判定を行うGem作ってみた qiita.com/moroku0519/ite… 文章のネガポジ判定例も探すとあるけど、今は深層学習を使うのが有力くさい。ちょっと大変そう。
2019-01-09 20:07:35
サンセット
@Sunset_Yuhi
N=5000の結果。Unix時間で記録されていた、コメントの投稿日時の情報などを追加。Day of weekは月曜0~日曜6とした曜日の変数。 やっぱり、View・Comment・Favoriteのどれか一方が多い記事で、グループが分かれそう。あと標本を取った中で、View数トップ3の記事は月曜日に作成されている。 pic.twitter.com/j1syHqG3b4
2019-01-13 21:28:28 拡大
拡大
 拡大
拡大
 拡大
サンセット
@Sunset_Yuhi
拡大
サンセット
@Sunset_Yuhi
記事を投稿した曜日、コメントを投稿した曜日、コメントを投稿した時間のヒストグラム。 記事は日曜(6)が投稿のピークである一方、コメントは木曜(3)が投稿のピークだった。土日(5,6)のコメント量は比較的少ない。 コメントの時間帯のピークは、昼休みと帰宅後頃にありそう。これは綺麗に出た。 pic.twitter.com/4dziB7Xpgh
2019-01-13 21:46:54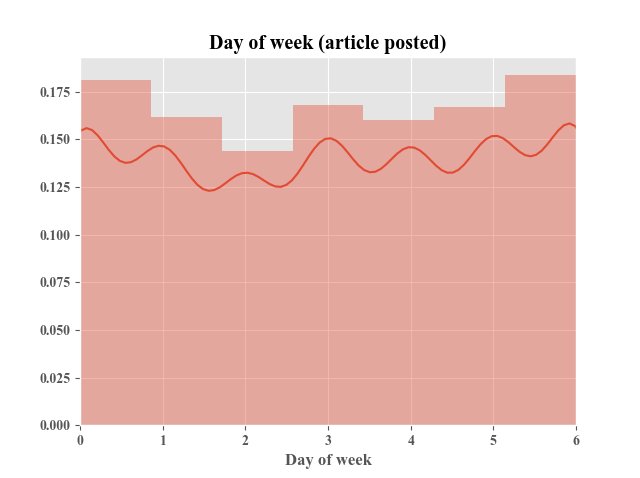 拡大
拡大
 拡大
拡大
 拡大
サンセット
@Sunset_Yuhi
拡大
サンセット
@Sunset_Yuhi
これ、5000ページのデータ取るのに30分くらいかかったので、1万ページで1時間が目安になりそう。しかし、2018年(約10万ページ)のデータを取ろうとしても、10時間以上かかることになるな~。kampferさんのデータを信用すれば、存在が確認されてる86000ページに直接アクセスできるけど。
2019-01-14 17:24:36
サンセット
@Sunset_Yuhi
2018年のコメントランキングのcsvを見てたら、すごいことが分かってしまった。1年間のコメントについて、1人当たりのコメント数の平均は42.137、中央値は3だった。つまり、コメントしたことある人の半分は、1年間に3回しか書き込んでいない。
2019-01-14 22:04:29