-

- いいね!539
 境 真良@iU/GLOCOM/METI(あーりん推し/芸能人スキャンダル要らない)
@sakaima
境 真良@iU/GLOCOM/METI(あーりん推し/芸能人スキャンダル要らない)
@sakaima
「令和」ですが、「令」はUnicode「U+4EE4」、UTF-8だと「E4 BB A4」、シフトJISだと「97DF」、また「和」はUnicode「U+548C」、UTF-8で「E5 92 8C」、シフトJISだと「9861」です。とりあえずご参考まで。 #さてお仕事ですよ
2019-04-01 11:46:49
BugbearR
@BugbearR
平成の次、新元号のUnicodeコードポイントは「U 32FF」 | マイナビニュース news.mynavi.jp/article/201809… #マイナビニュース
2019-04-01 17:24:53
プロ生ちゃん(暮井 慧)🍍
@pronama
おや!? U+32FF の ようすが……! #新元号 #プロ生ちゃん pic.twitter.com/4tpw0BX1Bg
2019-04-01 12:52:55
Taro Yabuki
@yabuki
U+FA98 unicode.org/cgi-bin/GetUni… は互換漢字,トラブルのもとです. たとえば, ・Twitterで使うと,U+FA98はU+4EE4に変わります. ・U+FA98とU+4EE4を(Ctrl+Fで)検索するときに同一視するかどうかはブラウザによります. お仕事がちょっと増えた人がいるかもしれません. pic.twitter.com/Ujg5dbXEN2
2019-04-01 13:00:57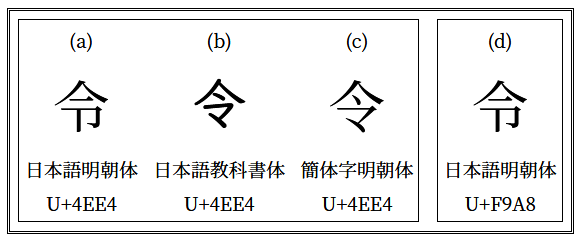 拡大
Haruhiko Okumura
@h_okumura
拡大
Haruhiko Okumura
@h_okumura
試してみる。 U+4EE4 令 U+F9A8 令 twitter.com/yabuki/status/…
2019-04-01 13:16:36
MAEDA Katsuyuki
@keikuma
年号扱うシステムを運用しているところは、これから30日でテスト完了させなきゃいけないわけだけど、U+F9A8 U+548C (令和) のケースと、U+4EE4 U+548C (令和) のケースがあるみたいなのを想定していなかった…って事例はなんかすごくありそう。大丈夫かなぁ…
2019-04-01 14:34:58
Haruhiko Okumura
@h_okumura
うちのEmacsだとU+F9A8はショボい字になる。I-searchでも同一視してくれない。いずれにせよU+4EE4で統一してほしい>令和 pic.twitter.com/Sxc11cz1Uw
2019-04-01 14:54:47 拡大
みずぴ⋈@NGS(5鯖)
@mizpy
拡大
みずぴ⋈@NGS(5鯖)
@mizpy
Unicodeで「令」の文字コードが2つあるのは KS X 1001 規格の弊害ですね…。(韓国で同じ漢字でも読みが異なる場合に別の文字コードを当てたのが原因) 基本的に日本国内で「令」を表示する場合はU+4EE4が使われているはず。
2019-04-01 15:58:15
なぎせ ゆうき
@nagise
「韓国の文字コード規格KS X 1001(収録当時の規格番号はKS C 5601)に含まれる重複漢字との往復変換を保証するために収録された漢字。」 とあるので、要するに韓国語の漢字ということになるか。 日本語で用いるならU+4EE4を用いるのが正解のようだ。
2019-04-01 16:00:10
㆑
@Wartemeinnicht
令︀(U+4EE4 U+FE00)「令(U+F9A8)がサニタイズされたようだな…」 令󠄀(U+4EE4 U+E0100)「フフフ…奴は四天王の中でも最弱…」 令󠄁(U+4EE4 U+E0101)「コードポイントではねられるとは異体字のツラ汚しよ…」 ちなみに手書き風の令󠄂(U+4EE4 U+E0102)もあります 747.github.io/vsselector/ pic.twitter.com/GjTjBGqVGy
2019-04-01 16:27:06 拡大
わっしー 왓시
@xhioe
拡大
わっしー 왓시
@xhioe
いや、U+F9A8は韓国語の頭音法則用に用意された互換漢字(령ではなく영の字として使用)なので日本語で使う選択肢は初めからないのですが…
2019-04-01 16:29:58
㆑
@Wartemeinnicht
むしろ「令和」では語頭に立つので、何かの手違いでKS X 1001式の変換を噛ませたU+F9A8が混入することが現実の可能性として発生する
2019-04-01 16:38:08
ちょまど@ ITエンジニア
@chomado
Adobe さん仕事早過ぎでは ーーー アドビのフォントが新元号「令和」に対応--2パターンの合字を追加 japan.cnet.com/article/351350…
2019-04-01 18:46:02
日本規格協会
@jsainfra
国際標準化機関のISO/IEC JTC1/SC2で、U+32FFの文字コードに割り当てられることが決定している/Adobeが新しい元号の“令和”の合字を小塚明朝や源ノ角ゴシックなどのフォントで追加 mdn.co.jp/di/newstopics/…
2019-04-02 09:28:16
zomysan
@zomysan
ブログを書きました。「 #令和 」の「令」は、Unicodeにおいて「U+4EE4」「U+F9A8」の2つの符号位置を持つ文字です。| CJK互換漢字とは?新元号「令和」の「令」Unicode符号に注意! – cod-log cod-sushi.com/unicode-rei/ pic.twitter.com/l7dvIRb7VH
2019-04-01 20:39:16 拡大
あきやま🍠
@akiyama924
拡大
あきやま🍠
@akiyama924
手書きOCRで、違うUnicodeにアサインされることが考えられるので、令和は2つの文字コードを持つ年号ということになることを考えてシステム設計しなければ。 pic.twitter.com/TmUeKGK8Pt
2019-04-01 17:58:02 拡大
BugbearR
@BugbearR
拡大
BugbearR
@BugbearR
メモ -- 新たな元号はJIS X 0213に入るのか | yasuokaの日記 | スラド srad.jp/~yasuoka/journ…
2019-04-02 13:26:55
むーくPっぽい
@MuhKurutsu
俺は、新元号の合字が、SJISには登録されなさそうで。 これで未来は古い文字コードと決別できそうと安心していたんだ。 IBM様 「新元号の合字は以下のコードにアサインされました。 EBCDIC: xE860」 🤔🤔🤔🤔🤔
2019-04-05 11:04:42
Tsukasa #01
@a4lg
マジカヨ!?と IBM のサポートページを見てみた。新元号発表前のページだけど、「対応するEBCDICとして CCSID 1399 に x'E860' として割り振られる予定です。 」……! www-01.ibm.com/support/docvie…
2019-04-05 23:40:53
The Unicode Consortium
@unicode
#新元号 #令和 の発表に迅速に対応、「令和」の合字を加えた #Unicode12_1 が近くリリースされます → bit.ly/Unicode12_1 #Reiwa 🇯🇵 pic.twitter.com/oQEd71IwC1
2019-04-29 09:56:02 拡大
The Unicode Consortium
@unicode
拡大
The Unicode Consortium
@unicode
#Unicode12_1 は #新元号#令和 の合字 U+32FF「SQUARE ERA NAME REIWA」一文字を加え、総文字数 137,929 個となります → bit.ly/Unicode12_1 #Reiwa 🇯🇵 pic.twitter.com/ZqgmJO6U9v
2019-04-30 09:34:40 拡大
The Unicode Consortium
@unicode
拡大
The Unicode Consortium
@unicode
✨🎉✨ 新時代の始まりに向けて #令和 の合字をサポートする #Unicode12_1 を準備中 → bit.ly/Unicode12_1 #新元号 #Reiwa 🇯🇵 pic.twitter.com/QxL45h533Y
2019-05-01 08:11:17 拡大
拡大