
囚人のジレンマの新しい戦略 ― 解説改
-
Hanpen_nepnaH
- 7346
- 0
- 1
- 0
-

- いいね!0
Lucas KBYS
@lkbys
(2) についての3。ぎりぎり matw.co の制限内で書けたので、D(p,q,f) を画像で http://t.co/WilBP0SV
2012-12-16 22:46:08 拡大
Lucas KBYS
@lkbys
拡大
Lucas KBYS
@lkbys
(2) についての4。この Iterated Prisoner's Dilemma をマルコフ過程と捉えているわけですけど、これには収束先が存在するので、それを表す横ベクトルをvとします。収束先でのXの利得s_Xは、S_X = (R,S,T,P) とvの内積です
2012-12-16 22:51:59
Lucas KBYS
@lkbys
(2) についての5。そしてこのs_Xが D(p,q,S_X) / D(p,q,1) と書ける……と、この論文は主張します。これはpやqの値によっては誤っているのですが、先に進みましょう
2012-12-16 22:54:31
Lucas KBYS
@lkbys
(3) についての1。 (2) が正しいとしましょう。すると、 α s_X + β s_Y + γ = D(p,q, α S_X + β S_Y + γ 1) / D(p,q,1) http://t.co/jLi8XCNQ
2012-12-16 23:06:51 拡大
Lucas KBYS
@lkbys
拡大
Lucas KBYS
@lkbys
(3) についての2。D(p,q,f) は行列式なので、もしも その2列目が α S_X + β S_Y + γ 1 となるように p や q を選べば、α s_X + β s_Y + γ = 0 これは3列目についても同様 http://t.co/sOr0x2r9
2012-12-16 23:20:36 拡大
Lucas KBYS
@lkbys
拡大
Lucas KBYS
@lkbys
(3) についての3。これが ZD strategyです。αなどはプレイヤーが設定可能。これを見た時点で、あまりに強力なので眉に唾をつけました
2012-12-16 23:25:23
Lucas KBYS
@lkbys
(4) について。ZD で、α=0 と置きます。すると、β と γ によって s_Y が表されます。 p_1 と p_4 で β と γ を消去。 p_1 と p_4 で p_2 と p_4 と s_Y が表されます
2012-12-16 23:28:35
Lucas KBYS
@lkbys
(5) について。ZDで β = 0 と置きます。(4) と同様の計算を試みるのですが、p_2 と p_3 が(p=(1,1,0,0) 以外では)0以上1以下の範囲に収まってくれません
2012-12-16 23:30:33
Lucas KBYS
@lkbys
(6) について。ZD で 行列式の2列目を φ ( (S_X - P 1) - χ (S_Y - P 1) ) にします。目的は「 (s_X -P) / (s_Y - P) の値を、Yの戦略と関係なく、Xの戦略だけで決定」 http://t.co/J62jwodE
2012-12-16 23:43:18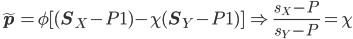 拡大
Lucas KBYS
@lkbys
拡大
Lucas KBYS
@lkbys
(6) について 2。当然、Xは変数χの値を1より大きく設定して、p_i が 0以上1以下となるように φ の値を決めます。このとき、s_X と s_Y が負にならないかというのは重大な関心事になりますが、このチェックは通るようです
2012-12-16 23:44:44
Lucas KBYS
@lkbys
(7) について1。 この (6) の条件下で、Yが( s_Y の gradient flow に沿ってqを変化させるという意味で)evolutionary なプレイヤーであると仮定します。gradient 方向は s_Y を最も急激に増加させる方向ですから、自然な仮定です
2012-12-16 23:50:01
Lucas KBYS
@lkbys
(7) についての2。Yがこのようにqを変化させた場合について、 (6) と同じ利得に収束するか、証明は与えられていませんが、そのかわりに典型例のグラフが示されています
2012-12-16 23:56:28
Lucas KBYS
@lkbys
(8) について。この部分、きちんと読めていません。雑に言って「マルコフ仮定の収束よりも早くYがqを変更する場合、マルコフ過程を用いた考察に意味があるのか?」という議論でしょう
2012-12-16 23:59:24
Lucas KBYS
@lkbys
(9) について。 http://t.co/lYdkPoWg http://t.co/5b7TnZvb http://t.co/2vqGvZ5M の辺りで書きました。Yにできるのは、「dを選択し続けるぞ」という脅しです
2012-12-17 00:02:44
Lucas KBYS
@lkbys
ここでYが、戦略 q_i を (0,0,0,0) に変更するとどうなるでしょうか? Yは常にdを採ります。古典的な囚人のジレンマの支配戦略であり、s_Y≧P が保証されます。Yがs_Yと1の差異を無視すれば(1とはPの値ですから)、Yにとって問題はありません
2012-12-12 01:57:24
Lucas KBYS
@lkbys
ところがこのYの戦略は、s_Xの値に影響を与えます。先ほどの計算では χ→+∞ のとき s_X→13/3 なのですが、Yが常にdを採るなら、s_Xは高々1 です
2012-12-12 02:02:19
Lucas KBYS
@lkbys
q=0 の場合、p_2 と p_4 の値、つまり、Yがdした場合のXの態度、によって、s_X と s_Y の値が決まります。Xにとっては、Yがdしか出さないのですから、Xもdを出し続けるのが最善です(当然ですね)
2012-12-17 00:13:48
Lucas KBYS
@lkbys
ああ、あと、q=0 かつ p_2 = 1 かつ p_4 = 0 の場合、マルコフの収束先は、一意には定まらず、初期条件で定まります。また、 q=0 かつ p_2 =0 かつ p_4 = 1 の場合、収束してくれません
2012-12-17 00:16:41
Lucas KBYS
@lkbys
定性的なことを言うと、自らの利得を増加させようとすると d を出す確率を上げざるを得ないのですから、まあ当然と言えば当然です
2012-12-17 00:27:22