-

- いいね!260
 小猫遊りょう(たかにゃし・りょう)
@jaguring1
小猫遊りょう(たかにゃし・りょう)
@jaguring1
マイクロソフトが機械読解 SQuAD2.0のスコアで人間のパフォーマンスにまた一歩近づけた(BERTを利用)。SQuAD1.1ではすでに人間のパフォーマンスを大幅に超えている。 SQuAD2.0 The Stanford Question Answering Dataset rajpurkar.github.io/SQuAD-explorer/ pic.twitter.com/nSM1uPK8JI
2019-01-24 17:23:58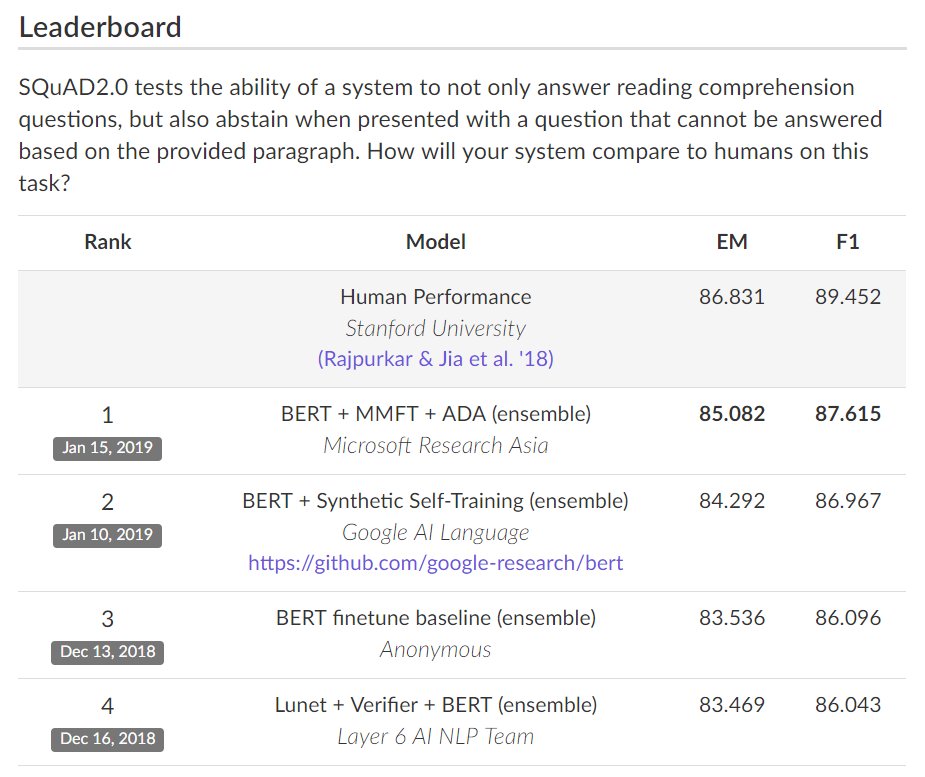 拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
SQuADデータセットにおけるリーダーボードは、ここで確認できる。 rajpurkar.github.io/SQuAD-explorer/
2018-12-18 19:37:13
小猫遊りょう(たかにゃし・りょう)
@jaguring1
グーグルが発表した「BERT」を使うと、SciTail データセットでもめっちゃ性能あがってる(Textual Entailment)。他の手法をぶっちぎってて、2位との差は+5.54%。93.84%へ飛躍。2位はOpenAIが半年ぐらい前に「沢山の言語理解タスクでけっこう性能向上した」って報告してたやつ leaderboard.allenai.org/scitail/submis… pic.twitter.com/LBsISxKBu8
2018-12-05 11:32:29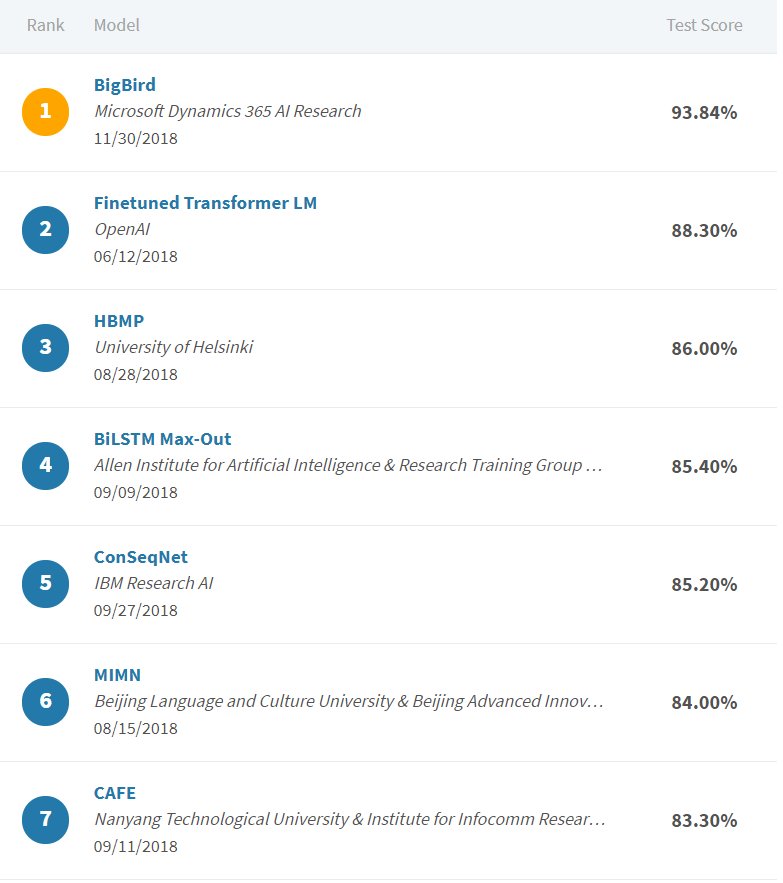 拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
BERTを用いた手法が、機械読解のCoQAデータセットにおいても最高性能を更新し続けている。(CoQAデータセットは、クラウドワーカーに記事を見せて、会話形式で質問応答してもらって作ったデータセット) CoQA : A Conversational Question Answering Challenge stanfordnlp.github.io/coqa/ pic.twitter.com/x7tsH0wQK0
2019-01-26 21:10:25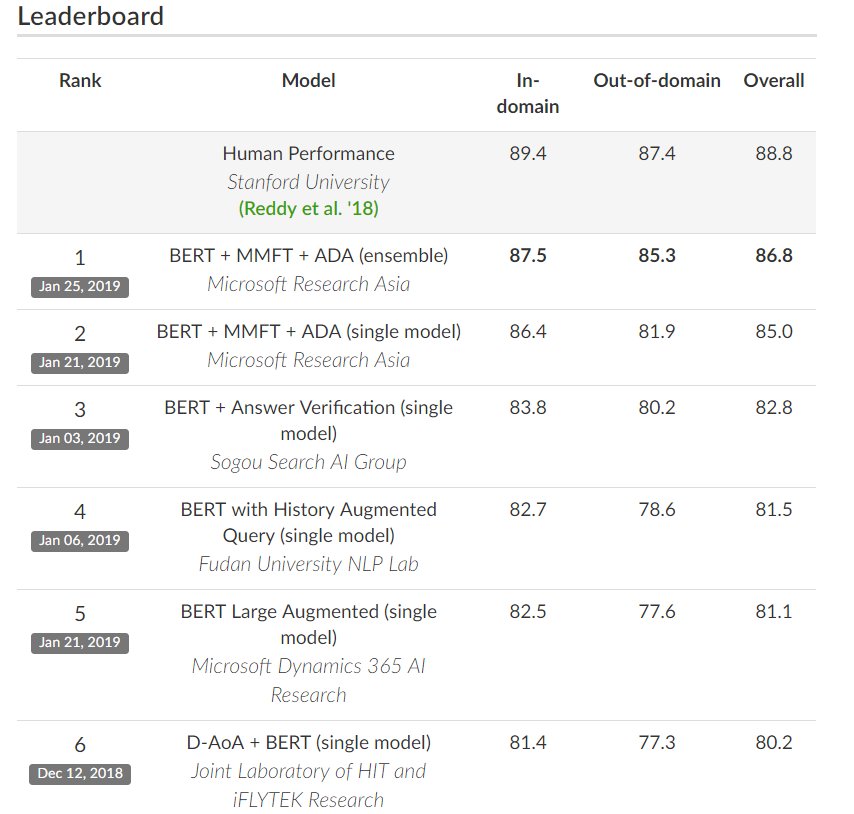 拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
ARCデータセット(小学生の理科の問題を読解用の形式にしたもの)でも順調に性能を伸ばしている。BERTが最高性能を更新。8ヵ月で+20%されてる。 pic.twitter.com/6rg1LpDbfV
2018-12-18 19:48:43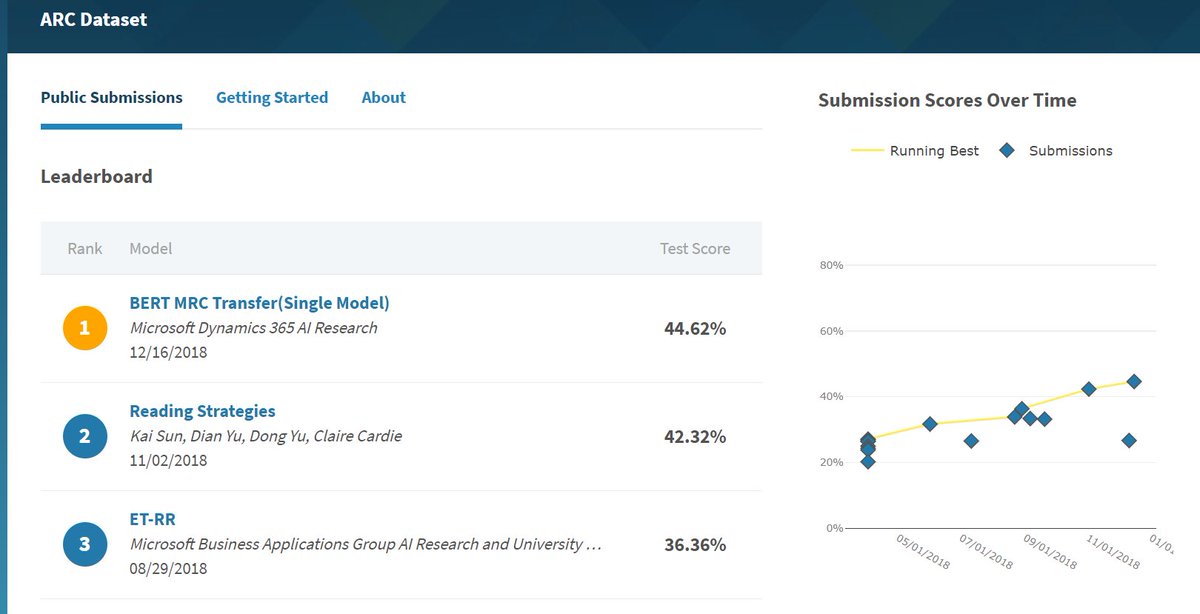 拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
ARCデータセットにおけるリーダーボードは、ここで確認できる。 leaderboard.allenai.org/arc/submission…
2018-12-18 19:49:54
小猫遊りょう(たかにゃし・りょう)
@jaguring1
OpenBookQA データセット(科学の基本的な知識が問われる問題を集めたデータセット)でも、BERTが最高性能を更新。この三か月ちょっとで+10%されてる。 pic.twitter.com/QpdVFzyWPs
2018-12-18 19:57:51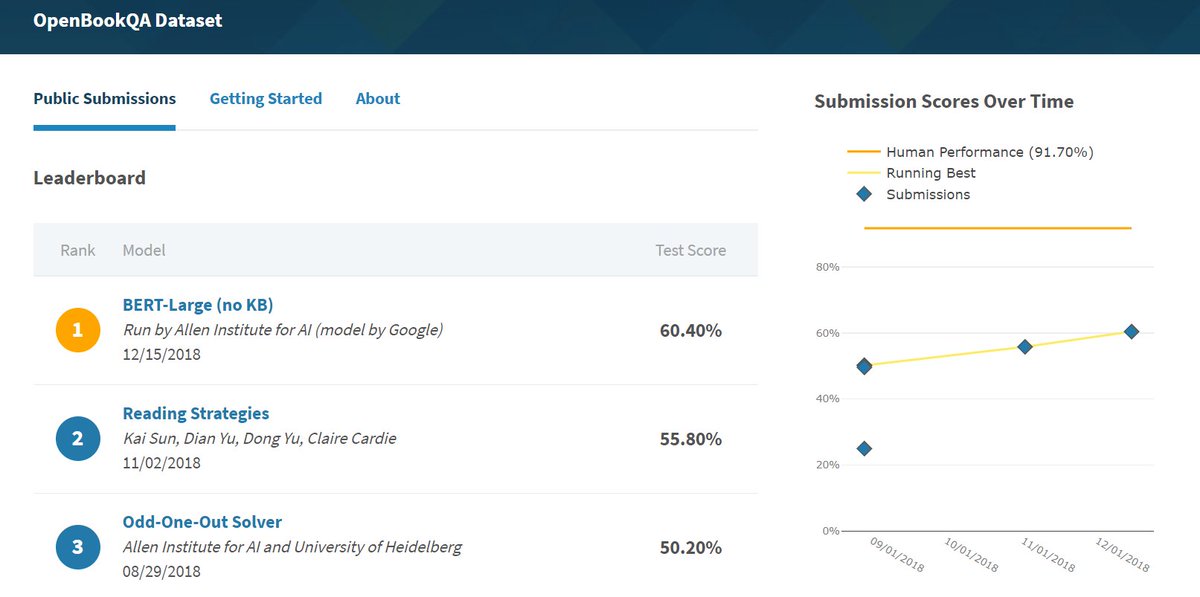 拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
OpenBookQA データセットのリーダーボードは、ここで確認できる。 leaderboard.allenai.org/open_book_qa/s…
2018-12-18 19:58:31
小猫遊りょう(たかにゃし・りょう)
@jaguring1
RACEデータセットは、中国の中高生の英語試験をベンチマークにしたもので、読解力に関するデータセット。東ロボの英語問題に比較的似ているデータセット。予想通り、ここにもBERTは使えた。着実にスコアが上がってきている。 RACE Reading Comprehension Dataset qizhexie.com/data/RACE_lead… pic.twitter.com/jleQiksUxv
2019-01-26 21:07:47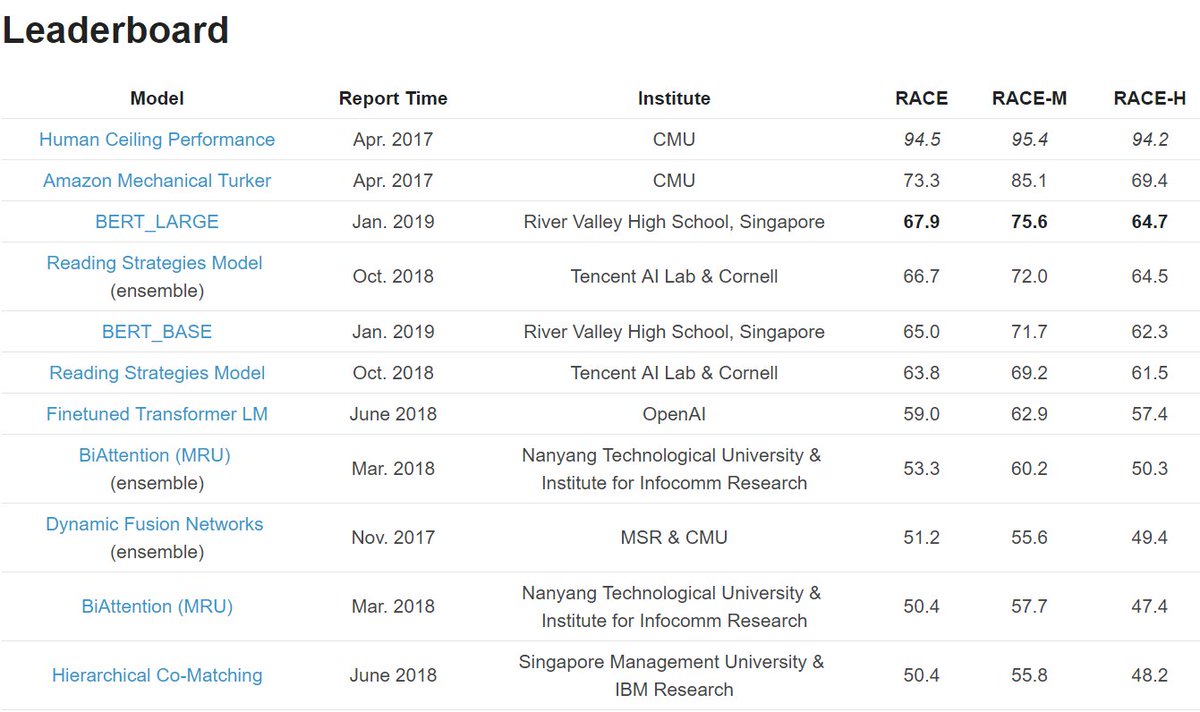 拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
パッセージ検索(リランキング)でBERTが利用されている(リーダーボードの1,2位両方とも) MS MARCO V2 Leaderboard msmarco.org/leaders.aspx pic.twitter.com/HqlsWXZhaY
2019-01-23 22:14:57 拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
拡大
小猫遊りょう(たかにゃし・りょう)
@jaguring1
良い記事 BERT with SentencePiece で日本語専用の pre-trained モデルを学習し、それを基にタスクを解く techlife.cookpad.com/entry/2018/12/… 「自分たちで学習した BERT が有用であることがひと目で理解できます」 「fine-tuning なので少量のデータで良い結果を出せるところが強力」 「応用上かなり有用」 pic.twitter.com/dl6NgwU0UG
2018-12-04 11:58:14 拡大
NVIDIA AI Developer
@NVIDIAAIDev
拡大
NVIDIA AI Developer
@NVIDIAAIDev
NVIDIA achieves 4x speedup on BERT (Bidirectional Encoder Representations from Transformers) neural network for NLP using Tensor Core GPUs. Learn how: nvda.ws/2ryy7TZ pic.twitter.com/2mq6VbZdKR
2018-12-13 07:35:01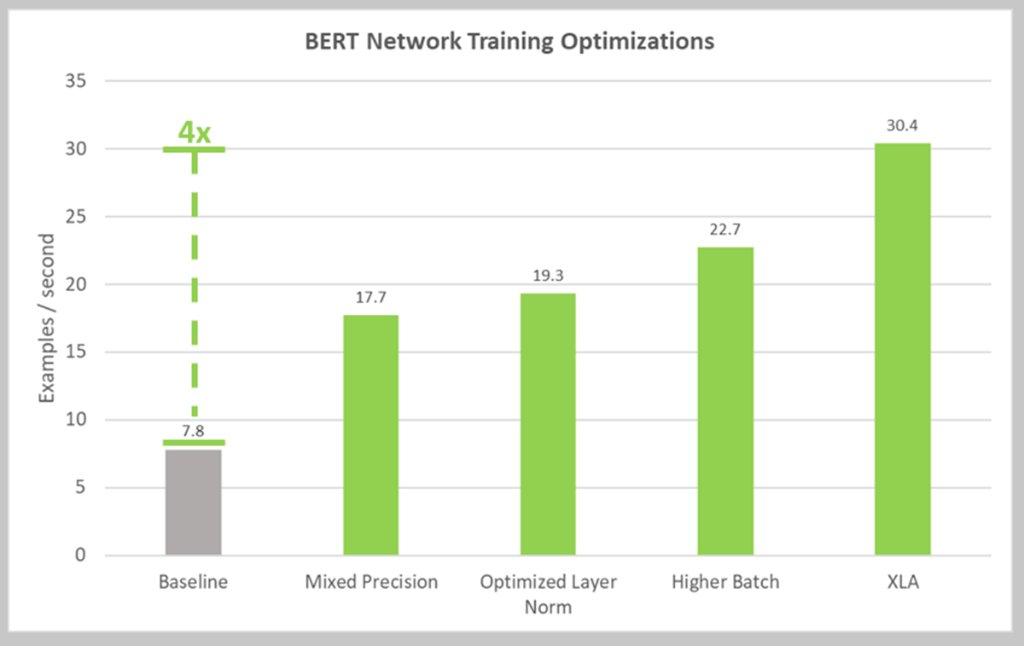 拡大
PyTorch
@PyTorch
拡大
PyTorch
@PyTorch
PyTorch BERT models are now 4x faster, thanks to @nvidia twitter.com/Thom_Wolf/stat…
2018-12-15 00:48:46
Thomas Wolf
@Thom_Wolf
Always amazed by what people do when you open-source your code! Here is pytorch-bert v0.4.0 in which - NVIDIA used their winning MLPerf competition techniques to make the model 4 times faster, - @rodgzilla added a multiple-choice model & how to fine-tune it on SWAG + many others! pic.twitter.com/8ujIfd3HUu
2018-12-14 23:40:55