-

- いいね!26
 詩音
@sionff
詩音
@sionff
Shibuya Synapse #2聴きにきてる。今日のお題は強化学習とゲームAI。難しいと言われる強化学習だけれど、要約するとつまりは「パブロフの犬」ということみたい。肝は適正な条件付けと報酬。未経験の事柄に対して報酬を設けることで「好奇心」を獲得するというのは目からウロコ。 pic.twitter.com/tmRJd4vOWQ
2017-11-23 15:09:10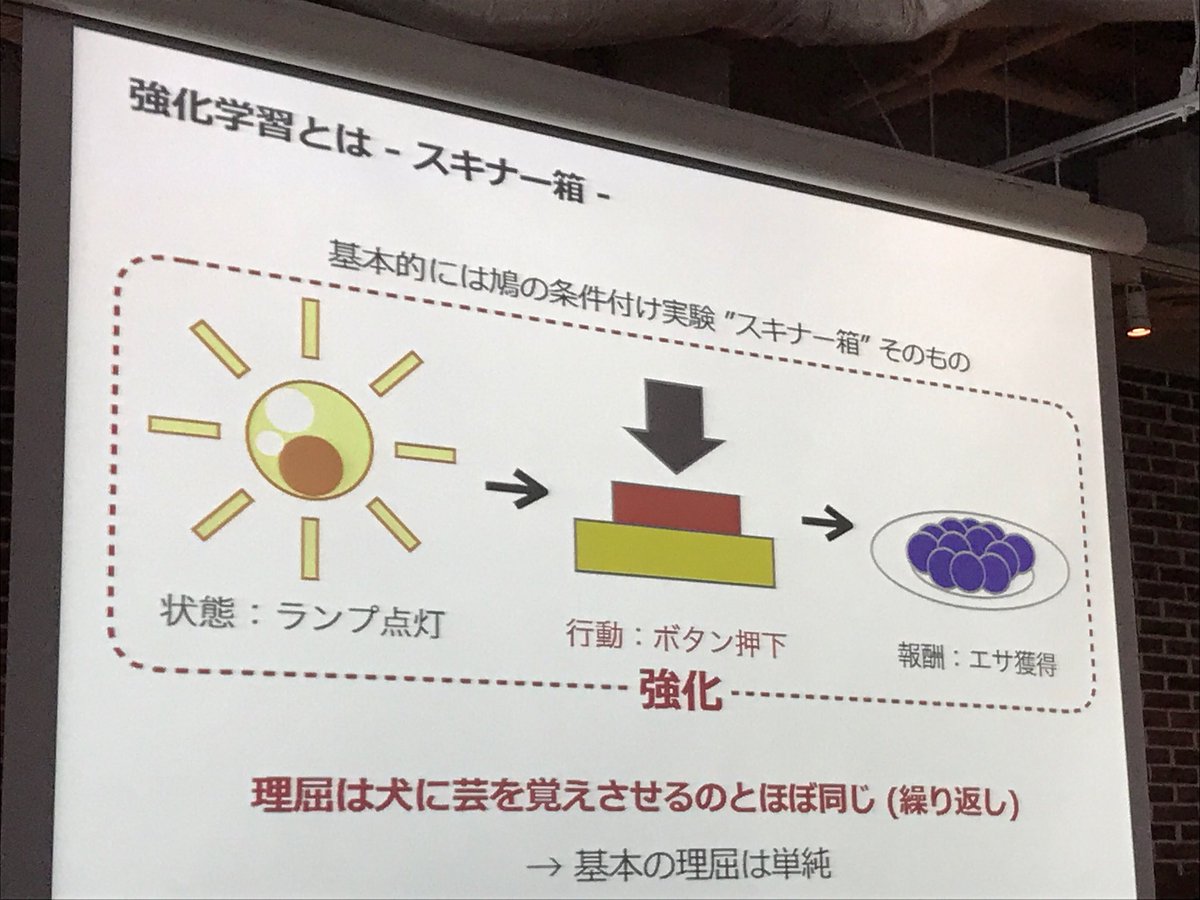 拡大
なっつー@BNUT
@yashinut
拡大
なっつー@BNUT
@yashinut
続いて HEROZの大渡さんから将棋プログラムPonanzaにおける強化学習とディープラーニングの応用 #shibuya_synapse
2017-11-23 15:11:28
詩音
@sionff
今度はPonanzaの話。完全情報ゲームだから基本は木探索、だけどコストを出来るだけ削減したいよね、で画像のような考え方になる。納得。 pic.twitter.com/QOHqfSic0a
2017-11-23 15:23:05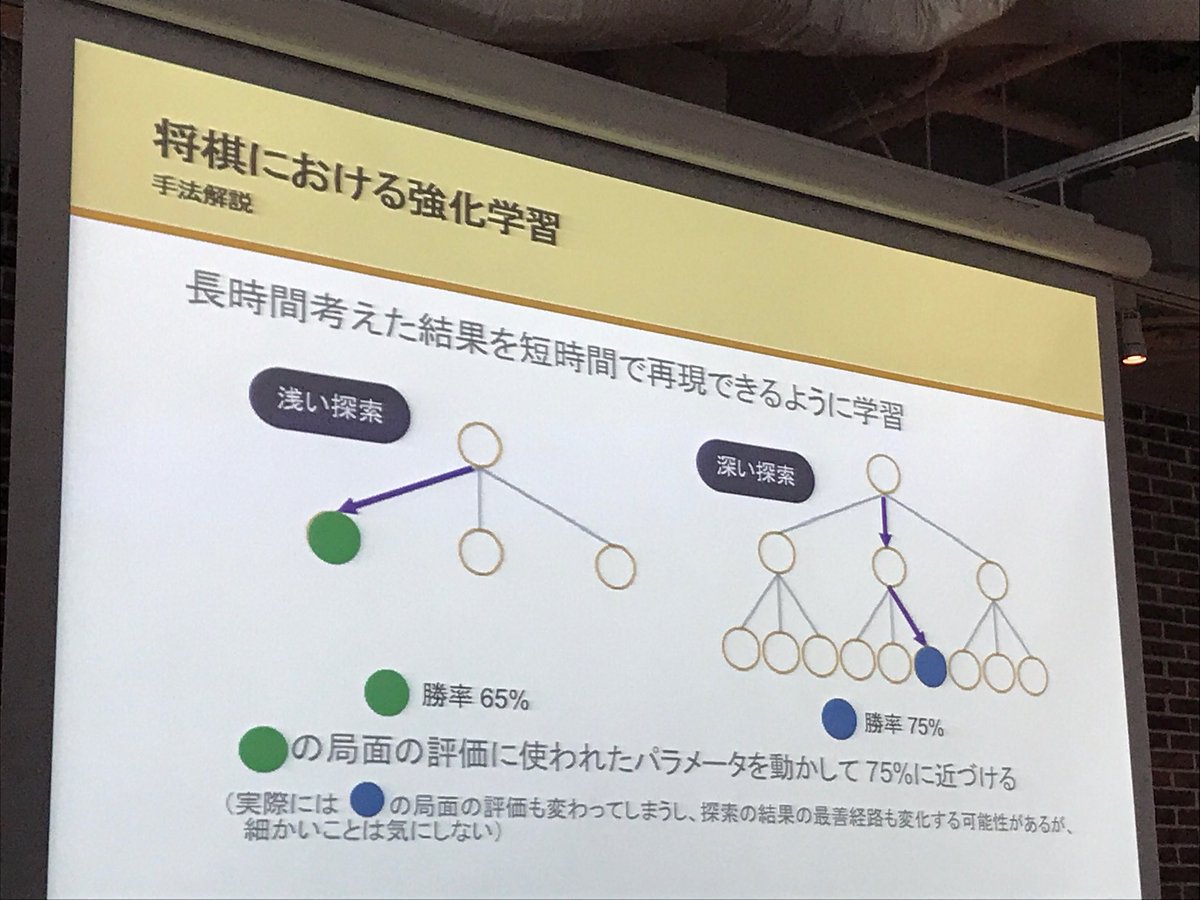 拡大
拡大
 keno
@keno_ss
keno
@keno_ss
Ponanza は 9x9x86 で 12 層 256 フィルタ. プレイヤー x チャネル(盤上の駒の種類 + 持ち駒) #shibuya_synapse
2017-11-23 15:29:39
keno
@keno_ss
詰みに繋がる駒の配置パターンがノイズになるので, ある程度間引いている. 25%〜75%の結果以外は学習しないと言われてたけど, NN 側の出力がそこに入ってない場合は妥当じゃないと見做して親の探索側で弾いてるってことかな? #shibuya_synapse
2017-11-23 15:39:45
keno
@keno_ss
1探索パス毎に NN 側への依頼は一回までと言われてたけど, ノード毎(局面毎)にやらないのは何でだろう? #shibuya_synapse
2017-11-23 15:45:57
詩音
@sionff
今回の講演のスライド公開してくれたらいいなー。後でゆっくり読み返したい。講演者の方のレベルが高くてかつ話が分かりやすくてかなり満足度高い。
2017-11-23 15:47:11
keno
@keno_ss
NN 側で 99.9 % みたいな結果が出たときは親探索側の探索を打ち切ってそれを選ぶという話で 2四歩の例が出てきたけど, 序盤って定石どれくらい使っているんだろう? #shibuya_synapse
2017-11-23 15:48:21