-

- いいね!0
 MAKIRINTARO
@MAKIRIN1230
MAKIRINTARO
@MAKIRIN1230
引用:それはケースコントロール研究の場合には結果のある群とそれにマッチするような結果のない群を集めて両群を比較するためである。つまり、結果のある母集団から結果のある群を無作為に抽出し、結果のない母集団から結果のない群を無作為に抽出してきているので、
2013-03-31 16:26:24
MAKIRINTARO
@MAKIRIN1230
引用:それらを横に結びつけて危険因子のある群とない群を作ってしまうと、それらは危険因子のある群の母集団とない群の母集団を代表しているとは言えないからである。結果のある群とない群の数をどれくらい集めるかは任意であるから、この表で横に合計する事は意味がないことが理解されると思う。
2013-03-31 16:27:13
MAKIRINTARO
@MAKIRIN1230
名言㊹「症例対照研究がリスクの推定においてコホート研究とコンパラティヴな結果を与える条件が何であるかわかっていないでござるな。自分の手を動かして計算すればすぐにわかることなのに教科書とか文献とかをナナメ読みして引用しているだけでは何もわからんでござるよ。」
2013-04-01 17:56:42
MAKIRINTARO
@MAKIRIN1230
まとめを更新しました。毎度のことですが、他人の話の内容が全く理解できないため、明後日の方向を向いた「藁人形論法」がお得意なようで・・・。 「hanageさんの爆笑迷言集」 http://t.co/vmzlKpoTFo
2013-04-01 18:08:33
MAKIRINTARO
@MAKIRIN1230
https://t.co/kekNN1GwoX 上図が母集団の被曝量の分布割合や平均値を反映していないということを分かっていない人が、チェルノブイリでの被曝量を実際より大きいと印象づけるために利用することを山下氏は計算したと思われる。 http://t.co/ozpvedSSye
2013-04-01 19:15:46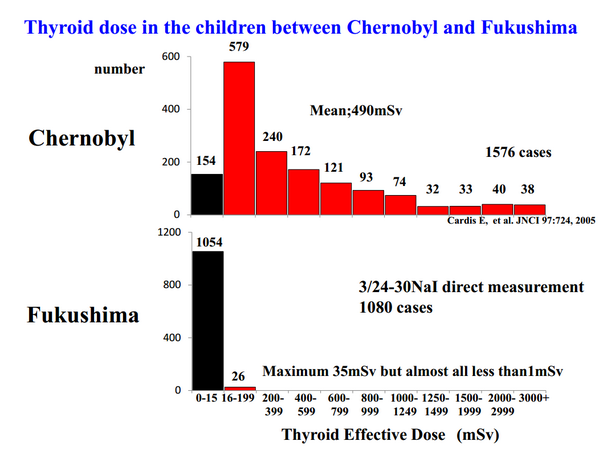 拡大
MAKIRINTARO
@MAKIRIN1230
拡大
MAKIRINTARO
@MAKIRIN1230
間違い探しクイズ(72)症例対照研究「で、牧野さんが問題にしている状況は、例えば分布がこんなことになってしまったことを意味していると考えられる。Aの場合、RR=4、OR=4.26に、Bの場合、RR=6、OR=6.68にそれぞれなる。http://t.co/1zsLdmrj」
2013-04-02 19:44:45
MAKIRINTARO
@MAKIRIN1230
症例対照研究では「RRもどき」ではなく「OR」を用いる理由すら理解できない人が、相変わらず、疫学について熟知しているフリをしているのはまことに滑稽である。
2013-04-03 19:06:34
MAKIRINTARO
@MAKIRIN1230
間違いを指摘されても訂正しない例(逆にdisり始める) http://t.co/ePu1XhLLnz http://t.co/jIx236BMCT http://t.co/VgnYCdhCCd http://t.co/ozpvedSSye
2013-04-03 19:45:19では、母集団とそこからサンプリングされるコホート研究、症例対照研究がそれぞれ母集団でのリスク因子曝露によるリスク増大を正しく評価できる理由とそのための条件を、あわせて「コホート研究のデータでは症例対照研究の計算方法が適用できる」理由を以下で示します。
 地下楽師@Ph.D
@tonkyo_Vc
地下楽師@Ph.D
@tonkyo_Vc
コホート研究の場合はこうやってサンプルを抽出する。なお、このときa+b=c+dである必要もないし、a+b≠A+B、c+d≠C+Dでも構わない。曝露群での発症リスクはa/(a+b)で、前提からa/(a+b)=A/(A+B)、(続く) http://t.co/sIMSekQKMC
2013-04-03 23:20:58 拡大
地下楽師@Ph.D
@tonkyo_Vc
拡大
地下楽師@Ph.D
@tonkyo_Vc
同様に非曝露群での発症リスクはc/(c+d)=C/(C+D)で、RR={a/(a+b)}/{c/(c+d)}={a(c+d)}/{(a+b)c}={A(C+D)}/{(A+B)C}になる。ところで、発症率が小さければ(癌などほとんどの疾患でそう)、A/(A+B)≒A/B、(続く)
2013-04-03 23:30:34
地下楽師@Ph.D
@tonkyo_Vc
C/(C+D)≒C/Dとなる。よって、コホート研究で得られたRRは母集団のRR{A(C+D)}/{(A+B)C}≒AD/BCになる。
2013-04-03 23:32:49
地下楽師@Ph.D
@tonkyo_Vc
一方、症例対照研究ではコホート研究が横のポピュレーションの比率が母集団と同一になるようにサンプルを抽出するのに対して縦のポピュレーションの比率が母集団と同じになるように抽出する。このとき、罹患群のオッズは(続く) http://t.co/oZ2DaPAaFb
2013-04-03 23:36:32 拡大
地下楽師@Ph.D
@tonkyo_Vc
拡大
地下楽師@Ph.D
@tonkyo_Vc
{a(a+c)}/{c(a+c)}、非罹患群のオッズは{b(b+d)}/{d(b+d)}になる。このとき、抽出条件から罹患群、非罹患群のオッズは{A(A+C)}/{C(A+C)}、{B(B+D)}/{D(B+D)}にそれぞれ等しくなる。ということで罹患群と非罹患群の(続く)
2013-04-03 23:40:06
地下楽師@Ph.D
@tonkyo_Vc
オッズ比は[{A/(A+C)}/{C/(A+C)}]/[{B/(B+D)}/{D/(B+D}]=AD/BCになるわけ。なので、別に横方向の数字が合っているとか合っていないとかどうでもよく、結果として母集団のAD/BCが症例対照研究で得られる(だから症例対照研究が意味あるわけ)。
2013-04-03 23:43:36
地下楽師@Ph.D
@tonkyo_Vc
だから、コホート研究のデータに対して症例対照研究の手法を適用してもOKだけど、症例対照研究のデータに対してコホート研究の手法を適用したら、{a(c+d)}/{(a+b)c}はa/(a+b)≠A/(A+B)、(c+d)/c≠(C+D)/Cなので、ダメ、ということになる。
2013-04-03 23:52:26
地下楽師@Ph.D
@tonkyo_Vc
的外れなdisりツイートしている暇があったら、少しアタマ使って考えればよいことなのだけど、まあそれは無理筋、っていうことかな。
2013-04-03 23:54:36
地下楽師@Ph.D
@tonkyo_Vc
@tonkyo_hanage あと追加だけど、様々な交絡が疫学研究の場合には発生するので、そういった交絡要因を層化したサブグループではここまで記したことが成立する、ということです。で、症例対照研究の場合、状況によってa/(a+b),c/(c+d)が変ってしまうので(続く)、
2013-04-04 00:04:13ここから更に何かわけのわからない計算が始まります。
つーか、私は症例対照研究に対してもコホート研究に対しても(a+b)/(c+d)=(A+B)/(C+D)などといった前提も結果もおいていないので(上のツイート見ればわかりますね)、自分で勝手にtonkyo_hanageは(a+b)/(c+d)=(A+B)/(C+D)と考えていると思い込んで話を進めているとしか思えません。まあ、そりゃ間違っている前提から出発したら間違った答えになりますがな(笑)。
MAKIRINTARO
@MAKIRIN1230
あそこまでやって、症例対照研究では(a+b)/(c+d)≠(A+B)/(C+D)になることが分からないとは・・・。可哀想すぎる。
2013-04-04 06:59:02
MAKIRINTARO
@MAKIRIN1230
論理的思考の苦手な人が「論理性の練習問題」というまとめを公開したが、厚顔無恥で破廉恥を極めただけのことはある内容であった。
2013-04-04 07:06:28
MAKIRINTARO
@MAKIRIN1230
一般的に示すには高校生程度の数学の力がいるかもしれないので、小学生でもわかる具体例で説明するなら、母集団についてA=160、B=40、C=200、D=800の場合、(A+B)/(C+D)=0.2。
2013-04-04 07:51:09